The data management community is increasingly interested in helping the larger scientific community organize, query, and process large data sets. I got to work on a really interesting bioinformatics problem this summer that involved a significant data processing and computational aspect. In the abstract, the problem is a learning task -- there are several items in a dataset, and each item has millions of features. Assume that each feature is categorical and can take one of three values. Each item is also associated with a set of "observations". Observations can be either categorical (eg. disease/no disease) or continuous. The objective is to predict the observations for unseen items.
This turns into a difficult model selection problem and various constraints are used from domain knowledge to reduce the space of possible models. For instance, consider the assumption that an observation can be explained using exactly one feature. Each of the features can be tested to see how well they can predict the observation using some learning technique (decision trees, regression, SVMs, etc.). If we find a good predictor, we also need to calculate a P-value. That is, the likelihood that such a good fit could have risen by chance. Furthermore, we may have to correct for the fact that we just evaluated millions of hypotheses (features). Multiple hypothesis testing in the statistical literature deals with assessing significance when many different statistical tests are performed. One of the techniques used ,when there's no easy closed-form technique for correcting for multiple hypotheses is to use permutations -- ie, the null hypothesis is that the observations have nothing to do with the actual features, so you hold the items in place, and randomly permute the observations. Any feature that is significant now is purely by chance. Repeating this computation a million times and finding only 1 good fit can be used to infer that the P-value is around 1 in a million, which is pretty significant.
The data sizes for this problem are small enough (in the tens or hundreds of gigabytes) that it can be solved on a single machine. But the processing demands are large enough that it makes sense to parallelize the solution. A traditional approach to solving this problem would have used an HPC-like setting. I worked with domain scientists to build a solution using several open source components including Hadoop, R, and RHIPE. In the coming weeks, I'll talk about what we learned from this approach -- what worked for the domain scientists, and what didn't. What parts helped increase the scientist's productivity and what hampered it.
Monday, December 5, 2011
Thursday, November 17, 2011
Analytic DBMS Landscape
Curt Monash has a great post describing eight kinds of analytic DBMSes. Here's a picture that presents a simplified view, but I highly recommend the original post. There are three major groups: the big enterprise data warehouses (EDWs), various kinds of data marts, and what he calls the "bit bucket" category -- which is where he places Hadoop. I've left out the "archival store" and the "operational analytic server" which was essentially a catch-all category.
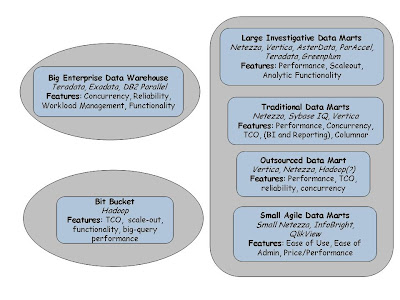
Let's look at Hadoop and related technologies -- Monash argues that this is the "big bit bucket" category. A place to gather large amounts of data cheaply and do some analytics .This is the kind of data that you'd normally consider too low-value to justify putting it inside your gold-plated EDW. As Hadoop gets better at TCO, performance, and adds better support for reporting, high-level analytics, and workload management -- how is it going to affect the other spaces? I've argued before that Hadoop is not going to be the next platform for EDWs for a long time to come.
One way to look at an improved Hadoop is as a bigger, more reliable, lower cost player in the "large investigative data mart" space. The investigative analytics aspect is likely to be Hadoop's major advantage along with low cost. Cheaper storage, better programmability, great fault-tolerance, and eventually reasonably good efficiency is going to make for a very interesting entry in the "large investigative data mart" space.
Traditional data marts are really good at being a data mart! Hadoop is a long way off from competing with those -- but there is probably a segment of this market that values elasticity and low-cost. My guess is startups like Platfora are going to target this space. I suspect very high scale marts that are not very demanding when it comes to concurrency and performance will very soon be better served by Hadoop-based solutions.
The unlikely category of "outsourced data marts" is actually quite promising. As workload management improves, it might be possible to consolidate large outsourced marts for reporting on Hadoop. Individual marts that are > 20PB are unlikely to be a large enough market (at least, not in the short term), but businesses that offer analytics on large datasets -- advertising tracking, clickstream analytics for customer modeling, website optimization, etc -- they will probably want a highly scalable, elastic, multi-tenant, low-cost mart.

Let's look at Hadoop and related technologies -- Monash argues that this is the "big bit bucket" category. A place to gather large amounts of data cheaply and do some analytics .This is the kind of data that you'd normally consider too low-value to justify putting it inside your gold-plated EDW. As Hadoop gets better at TCO, performance, and adds better support for reporting, high-level analytics, and workload management -- how is it going to affect the other spaces? I've argued before that Hadoop is not going to be the next platform for EDWs for a long time to come.
One way to look at an improved Hadoop is as a bigger, more reliable, lower cost player in the "large investigative data mart" space. The investigative analytics aspect is likely to be Hadoop's major advantage along with low cost. Cheaper storage, better programmability, great fault-tolerance, and eventually reasonably good efficiency is going to make for a very interesting entry in the "large investigative data mart" space.
Traditional data marts are really good at being a data mart! Hadoop is a long way off from competing with those -- but there is probably a segment of this market that values elasticity and low-cost. My guess is startups like Platfora are going to target this space. I suspect very high scale marts that are not very demanding when it comes to concurrency and performance will very soon be better served by Hadoop-based solutions.
The unlikely category of "outsourced data marts" is actually quite promising. As workload management improves, it might be possible to consolidate large outsourced marts for reporting on Hadoop. Individual marts that are > 20PB are unlikely to be a large enough market (at least, not in the short term), but businesses that offer analytics on large datasets -- advertising tracking, clickstream analytics for customer modeling, website optimization, etc -- they will probably want a highly scalable, elastic, multi-tenant, low-cost mart.
Tuesday, November 15, 2011
Big Data and Hardware Trends
One of the common refrains from "real" data warehouse folks when it comes to data processing on Hadoop is the assumption that a system built in Java is going to be extremely inefficient for many tasks. This is quite true today. However, for managing large datasets, I wonder if that's the right way to look at it. CPU cycles available per dollar is decreasing more rapidly than sequential bandwidth available per dollar. Dave Patterson observed this a long time ago. He noted that the annual improvement rate for CPU cycles is about 1.5x and the improvement rate for disk bandwidth was about 1.3x ... and there seems to be evidence that the disk bandwidth improvements are tapering off.
While SSDs remain expensive for sheer capacity, disks will continue to store most of the petabytes of "big data". A standard 2U server can only hold so many disks .. you max out at about 16 2.5" disks or about 8-10 3.5" disks. This gives us about 1500MB/s of aggregate sequential bandwidth. You can stuff 48 cores into a 2U server today. This number will probably be around 200 cores in 3-4 years. Even with improvements in disk bandwidth, I'd be surprised if we could get more than 2000MB/s in 3-4 years using disks. In the meantime, the JVMs will likely close the gap in CPU efficiency. In other words, the penalty for being in Java and therefore CPU inefficient is likely to get progressively smaller.
There are lots of assumptions in the arguments above, but if they line up, it means that Hadoop-based data management solutions might start to get competitive with current SQL engines for simple workloads on very large datasets.The Tenzing folks were claiming that this is already the case with a C/C++ based MapReduce engine.
While SSDs remain expensive for sheer capacity, disks will continue to store most of the petabytes of "big data". A standard 2U server can only hold so many disks .. you max out at about 16 2.5" disks or about 8-10 3.5" disks. This gives us about 1500MB/s of aggregate sequential bandwidth. You can stuff 48 cores into a 2U server today. This number will probably be around 200 cores in 3-4 years. Even with improvements in disk bandwidth, I'd be surprised if we could get more than 2000MB/s in 3-4 years using disks. In the meantime, the JVMs will likely close the gap in CPU efficiency. In other words, the penalty for being in Java and therefore CPU inefficient is likely to get progressively smaller.
There are lots of assumptions in the arguments above, but if they line up, it means that Hadoop-based data management solutions might start to get competitive with current SQL engines for simple workloads on very large datasets.The Tenzing folks were claiming that this is already the case with a C/C++ based MapReduce engine.
Tuesday, October 11, 2011
Data Management and Machine Learning
Victor, Hogwild, Felix, Tuffy: Chris Re has been doing some very interesting work at the intersection of databases and machine learning at the University of Wisconsin. Victor proposes to support many kinds of learning tasks that can be solved using Stochastic Gradient Descent (SGD) in a traditional relational database. Victor provides a python interface to design your learning task and it is executed using the UDF mechanism available in the database. They show that it is not particularly hard to solve a variety of statistical problems with this infrastructure. As expected linear models, such as logistic regression can easily be implemented. The examples go on to show conditional random fields, min-cut, and factored models.
Felix is a relational optimizer for statistical inference. In particular, if you want to solve a Markov Logic Network based on data sitting in some database (say postgres), Felix is your guy. Check out this example. In a VLDB paper this year they describe a system called Tuffy -- one of the components that Felix uses. I haven't had to play with Bayesian Networks or Graphical Models since my machine learning course back in grad school, so I can more easily see the applicability of regression and factored models compared with MLNs :-) Any pointers to applications where MLNs have been used successfully to solve big-data learning tasks will be much appreciated.
A recent paper (HOGWILD) points out some very interesting results on parallelizing SGD algorithms. SGD is an incredibly convenient way to deal with large data sets while trying to learn statistical models. A particularly thorny issue of parallelizing an SGD algorithm is one of concurrent updates to a shared model from different threads. While standard techniques of locking and synchronization can be used to make sure updates to the model follow some serial order, they often end up being the critical performance bottleneck.
In HOGWILD, the authors show that for optimization problems where the model is sparse, that is concurrent updates have a low probability of causing conflicting updates, it is reasonable to proceed with the updates without locking or synchronization. While this might cause some threads (or processes) to occasionally over-write each other's work, the convergence rate is still close to optimal. On several machine learning tasks, such as matrix factorization and learning sparse SVMs -- they show that HOGWILD is at least as as good and often substantially faster than known serial methods and previous parallel techniques. This is a really cool result, and I've used it in a different context in my current research with impressive results! I'll describe that work in the coming weeks...
Felix is a relational optimizer for statistical inference. In particular, if you want to solve a Markov Logic Network based on data sitting in some database (say postgres), Felix is your guy. Check out this example. In a VLDB paper this year they describe a system called Tuffy -- one of the components that Felix uses. I haven't had to play with Bayesian Networks or Graphical Models since my machine learning course back in grad school, so I can more easily see the applicability of regression and factored models compared with MLNs :-) Any pointers to applications where MLNs have been used successfully to solve big-data learning tasks will be much appreciated.
A recent paper (HOGWILD) points out some very interesting results on parallelizing SGD algorithms. SGD is an incredibly convenient way to deal with large data sets while trying to learn statistical models. A particularly thorny issue of parallelizing an SGD algorithm is one of concurrent updates to a shared model from different threads. While standard techniques of locking and synchronization can be used to make sure updates to the model follow some serial order, they often end up being the critical performance bottleneck.
In HOGWILD, the authors show that for optimization problems where the model is sparse, that is concurrent updates have a low probability of causing conflicting updates, it is reasonable to proceed with the updates without locking or synchronization. While this might cause some threads (or processes) to occasionally over-write each other's work, the convergence rate is still close to optimal. On several machine learning tasks, such as matrix factorization and learning sparse SVMs -- they show that HOGWILD is at least as as good and often substantially faster than known serial methods and previous parallel techniques. This is a really cool result, and I've used it in a different context in my current research with impressive results! I'll describe that work in the coming weeks...
Tuesday, October 4, 2011
Tenzing: SQL on MapReduce
Google described Tenzing, their implementation of SQL on MapReduce at VLDB this year. The paper explains that they built it because their data-warehouse was getting too expensive and was not able to keep pace with the demands the users made -- in terms of complex queries (SQL was always getting in the way), and performance (the ETL process was often a big bottleneck). Neither argument is particularly surprising, although there are examples of successful PB-sized warehouses in the industry.
One of the most interesting parts of the paper was a laundry list of things they had to fix in MapReduce to get better performance for SQL:
What does this mean for the Apache Hadoop ecosystem? I'm guessing the biggest performance opportunities for Hive currently lie in making the execution engine more CPU efficient. In fact, an experimental branch of Hive that does this would probably be a really fun open-source project right now. Hadoop will likely incorporate some of the performance improvements described in Tenzing over time, and Hive should be able to ride those when they become available.
One of the most interesting parts of the paper was a laundry list of things they had to fix in MapReduce to get better performance for SQL:
- Workerpools: These are essentially long running processes that do various parts of the MapReduce job (map task, reduce task, job coordinator, etc). Having a pool of running processes makes latencies lower than they would be if you had to launch a binary for each task in the job. This is certainly the case with JVM launches in Hadoop. Hadoop gets part of this done with reusable JVMs. The tradeoff, of course, is that fault isolation becomes a messier proposition.
- Streaming and In-Memory Chaining: Allows two MapReduce jobs to communicate without temping to disk (GFS). I wonder if this can be done easily with just some InputFormat/OutputFormat magic ... I suspect this is do-able with some thought. Memory-chaining allows a mapper and a reducer to be co-located in the same process. This is probably going to be a bit harder to do in Hadoop.
- Sort Avoidance: This feature allowed you to tell MapReduce to shuffle, but not sort. I've seen the need for this in many applications. Again, makes perfect sense for Hadoop also.
- Block Shuffle: For smaller rows, when sorting is not needed, the block shuffle reduces overheads in the shuffle phase. This is a performance opportunity opened up by sort avoidance.
What does this mean for the Apache Hadoop ecosystem? I'm guessing the biggest performance opportunities for Hive currently lie in making the execution engine more CPU efficient. In fact, an experimental branch of Hive that does this would probably be a really fun open-source project right now. Hadoop will likely incorporate some of the performance improvements described in Tenzing over time, and Hive should be able to ride those when they become available.
Tuesday, September 20, 2011
Parallel Stochastic Gradient Descent
I've been learning about stochastic gradient descent (SGD) and why people seem to be excited about it in the context of building models over large datasets. Rainer Gemulla, Peter Haas, Erik Nijcamp, and Yannis Sismanis published a really cool paper at KDD this year that was my introduction to the problem.
At a high level. SGD is simply an optimization technique that can be used to minimize some objective function (such as a loss function). The main difference from traditional "batch" gradient descent is that SGD samples from the data at each step. That is, the model can be updated after evaluating the gradient of the loss function for a sample of the input data -- a sample that can be as small as a single point! SGD can achieve incredibly fast performance on a variety of machine learning tasks -- and often converges to a good solution much faster than conventional batch gradient descent. On large data sets, the performance difference could be an order of magnitude or more. There are, of course, lots of caveats about data size, learning rates, sampling techniques, and convergence rates, when it comes to SGD.
The KDD paper focuses on matrix factorization -- a technique that has received a lot of interest in the context of the "Netflix Problem". Given a sparse C by I matrix M of C customers and I items (say movies), where each entry in the matrix contains a rating, the problem is one of finding factors of the matrix A , B such that the matrix M' = A x B matches the existing values in M, and offers a prediction for the missing values in M. There are many techniques for solving this problem. However, as the matrix M gets larger, and you have billions of ratings from millions of customers, the problem becomes too big to solve on a single machine.
Rainer's KDD paper shows how you can use a distributed version of SGD to solve this problem using a cluster of machines. The central idea in the paper is a clever partitioning of the matrix so that each node in the cluster can work on a partition of the data and update the model (the factors A and B) without fine grained coordination with other nodes in the cluster. The bulk of the paper deals with proving why their partitioning strategy is statistically sound. The paper describes an implementation of this using R and Snowfall for small clusters. They also describe an implementation of this algorithm using Hadoop. The details of the implementation are tricky and complicated -- you need to achieve a certain partitioning of the data, there are certain communication patterns on the model that are not a natural fit for Hadoop resulting in some inelegant MapReduce code, and a certain amount of additional coordination is required for efficient performance. However, the results are impressive -- the Distributed SGD algorithm converges to a good solution faster and scales way better than alternative techniques.
As one can imagine, Netflix isn't the only company that needs to solve large recommendation problems. There are many large content publishers, marketplaces, and retailers working hard on good solutions to this problem. What's more, the ability to factorize large matrices is good not just for content recommendation. It can be used as a building block for clustering algorithms, topic detection, and even risk analytics. Neat stuff. This should enable some interesting new recommendation-style applications and provide alternate/faster implementations for existing ones.
At a high level. SGD is simply an optimization technique that can be used to minimize some objective function (such as a loss function). The main difference from traditional "batch" gradient descent is that SGD samples from the data at each step. That is, the model can be updated after evaluating the gradient of the loss function for a sample of the input data -- a sample that can be as small as a single point! SGD can achieve incredibly fast performance on a variety of machine learning tasks -- and often converges to a good solution much faster than conventional batch gradient descent. On large data sets, the performance difference could be an order of magnitude or more. There are, of course, lots of caveats about data size, learning rates, sampling techniques, and convergence rates, when it comes to SGD.
The KDD paper focuses on matrix factorization -- a technique that has received a lot of interest in the context of the "Netflix Problem". Given a sparse C by I matrix M of C customers and I items (say movies), where each entry in the matrix contains a rating, the problem is one of finding factors of the matrix A , B such that the matrix M' = A x B matches the existing values in M, and offers a prediction for the missing values in M. There are many techniques for solving this problem. However, as the matrix M gets larger, and you have billions of ratings from millions of customers, the problem becomes too big to solve on a single machine.
Rainer's KDD paper shows how you can use a distributed version of SGD to solve this problem using a cluster of machines. The central idea in the paper is a clever partitioning of the matrix so that each node in the cluster can work on a partition of the data and update the model (the factors A and B) without fine grained coordination with other nodes in the cluster. The bulk of the paper deals with proving why their partitioning strategy is statistically sound. The paper describes an implementation of this using R and Snowfall for small clusters. They also describe an implementation of this algorithm using Hadoop. The details of the implementation are tricky and complicated -- you need to achieve a certain partitioning of the data, there are certain communication patterns on the model that are not a natural fit for Hadoop resulting in some inelegant MapReduce code, and a certain amount of additional coordination is required for efficient performance. However, the results are impressive -- the Distributed SGD algorithm converges to a good solution faster and scales way better than alternative techniques.
As one can imagine, Netflix isn't the only company that needs to solve large recommendation problems. There are many large content publishers, marketplaces, and retailers working hard on good solutions to this problem. What's more, the ability to factorize large matrices is good not just for content recommendation. It can be used as a building block for clustering algorithms, topic detection, and even risk analytics. Neat stuff. This should enable some interesting new recommendation-style applications and provide alternate/faster implementations for existing ones.
Thursday, September 15, 2011
New Ideas In Datacenter Networking
I've recently been stumbling into interesting papers on new ways to wire up datacenters to guarantee properties like high bisection bandwidth without the need for expensive networking hardware like big second level switches. I don't normally read a lot about networking but some of the stuff I've been working on lately has given me a peek into the SIGCOMM, NSDI world ...
CamCube, BCube, and DCell all seem to be exploring ways of giving up the big expensive switch at the top of a tree-structured network in favor of multiple NICs on each server and/or multiple smaller switches connected in interesting topologies. I suspect this is still very early stage stuff, and many problems such as cabling, servicability, availability NIC-to-NIC transfer without burning CPU etc need to be solved before it becomes interesting to a practitioner. But the papers do offer an intriguing read for someone who normally follows the database and systems communities.
In the Hadoop/MapReduce context, this could change how we think about scheduling tasks, scheduling transfers when multiple MapReduce jobs are running. One of the papers actually talks about how Hadoop workloads could be affected by these new topologies. One criticism against these approaches in the context of Hadoop clusters is that they probably only get interesting for mid-to-large clusters. Monash reports that the median Hadoop cluster is about 30 nodes and that the average is about 200 nodes (numbers courtesy Omer Trajman of Cloudera). At these sizes, there are cheaper and easier ways to wire up a Hadoop cluster. Fun papers nevertheless!
CamCube, BCube, and DCell all seem to be exploring ways of giving up the big expensive switch at the top of a tree-structured network in favor of multiple NICs on each server and/or multiple smaller switches connected in interesting topologies. I suspect this is still very early stage stuff, and many problems such as cabling, servicability, availability NIC-to-NIC transfer without burning CPU etc need to be solved before it becomes interesting to a practitioner. But the papers do offer an intriguing read for someone who normally follows the database and systems communities.
In the Hadoop/MapReduce context, this could change how we think about scheduling tasks, scheduling transfers when multiple MapReduce jobs are running. One of the papers actually talks about how Hadoop workloads could be affected by these new topologies. One criticism against these approaches in the context of Hadoop clusters is that they probably only get interesting for mid-to-large clusters. Monash reports that the median Hadoop cluster is about 30 nodes and that the average is about 200 nodes (numbers courtesy Omer Trajman of Cloudera). At these sizes, there are cheaper and easier ways to wire up a Hadoop cluster. Fun papers nevertheless!
Thursday, September 8, 2011
Spinnaker VLDB Slides
[edit] Here's the full presentation I used at VLDB:
Here's a subset of the slides I used at VLDB comparing Spinnaker with Bigtable, Dynamo, and PNUTS:






Spinnaker VLDB 2011
View more presentations from sandeep_tata
Here's a subset of the slides I used at VLDB comparing Spinnaker with Bigtable, Dynamo, and PNUTS:






Sunday, September 4, 2011
VLDB 2011
I was at VLDB last week. I got to see a bunch of interesting talks and had several fun hallway conversations
Here are some notes from the conference:
Challenges and Vision Track
The Challenges and Vision track was probably the most fun. Two talks stood out to me (although I didn't attend all the talks in this session). Magdalena Balazinska's talk on Data Markets and Peter Haas' "Data is Dead -- Without What If Models". Magda's argument was that public clouds are turning out to be a very convenient place to buy and sell data and research is required to understand how data and data services can be priced and sold. She argued that the current tiered subscription models don't really cut it (I'm not sure I fully buy it, but it is an interesting proposition). She argued that this brings about many challenges at the intersection of databases and economics.
Peter Haas (who also works at IBM Almaden) argued that the database community has traditionally been good at descriptive statistics and shallow models, but will need to get good at supporting deep, predictive models to really unlock the value of all the data we're gathering. He gave examples from the healthcare world and the weather simulation world on how deeper models help us ask harder "what-if" questions. In effect he was challenging the data management community to reinvent itself as the "data and model management" community.
Traditional Database Research
Thomas Neumann of MPI gave a fun talk about compiled query processing for modern architectures.He argued that giving compilers a fighting chance to optimize your query plan after generating it in C++ (or LLVM) can be really good for query performance. In fact, with modern architectures, this might be required to get much better performance than the iterator pipelining model used in many commercial runtimes. Much of this builds on the observations that the MonetDB guys have made in the context of columnar processing techniques and the overheads of row-oriented operator pipelining-based runtimes, I expect this will be a good paper to read.
RemusDB, the best paper award winner, was an interesting talk that showed how VM-replication now performs well enough to be a way to provide High-Availability for any arbitrary database implementation. While this approach does make for a quick-and-dirty HA solution that deals with the primary failing, I'm not sure a VM level solution would work when the failed primary restarts and wants to rejoin the master-slave pair. Nevertheless, this will probably make a fun read for anyone interested in database systems.
HyPer -- a demo from some of the guys at TU-Munich , HYRISE -- from HPI and several others in academia have been playing with ideas for main-memory systems that can provide good OLTP performance while also supporting a reasonable OLAP workload. Their argument is that in most cases, you don't really need to have two separate systems -- one for OLTP and one for OLAP. I guess it is back to "one-size fits all" now eh?
There was also a cool paper on serializable snaphot isolation for replicated databases optimized for high update rates from folks at the University of Sydney and Seoul National University.
Industrial Talks
Google described Tenzing a SQL engine on MapReduce. The interesting part was that they worked with the MapReduce team quite a bit to make it possible to implement reasonably efficient join plans. The speaker flashed some slides that seemed to indicate that the per-node performance of Tenzing was "comparable" to a commercial database.
Ben Reed talked about "Inspector Gadget" -- a debugging tool for Pig that is currently in use at Yahoo! and has been open sourced as part of Pig 0.9.
Other Stuff
There were a bunch of interesting efforts around Hadoop and MapReduce that I'll write about in more detail later. There seemed to be some interest at the intersection of crowdsourcing and databases -- I'm still not sure I understand the opportunities there.
Here are some notes from the conference:
Challenges and Vision Track
The Challenges and Vision track was probably the most fun. Two talks stood out to me (although I didn't attend all the talks in this session). Magdalena Balazinska's talk on Data Markets and Peter Haas' "Data is Dead -- Without What If Models". Magda's argument was that public clouds are turning out to be a very convenient place to buy and sell data and research is required to understand how data and data services can be priced and sold. She argued that the current tiered subscription models don't really cut it (I'm not sure I fully buy it, but it is an interesting proposition). She argued that this brings about many challenges at the intersection of databases and economics.
Peter Haas (who also works at IBM Almaden) argued that the database community has traditionally been good at descriptive statistics and shallow models, but will need to get good at supporting deep, predictive models to really unlock the value of all the data we're gathering. He gave examples from the healthcare world and the weather simulation world on how deeper models help us ask harder "what-if" questions. In effect he was challenging the data management community to reinvent itself as the "data and model management" community.
Traditional Database Research
Thomas Neumann of MPI gave a fun talk about compiled query processing for modern architectures.He argued that giving compilers a fighting chance to optimize your query plan after generating it in C++ (or LLVM) can be really good for query performance. In fact, with modern architectures, this might be required to get much better performance than the iterator pipelining model used in many commercial runtimes. Much of this builds on the observations that the MonetDB guys have made in the context of columnar processing techniques and the overheads of row-oriented operator pipelining-based runtimes, I expect this will be a good paper to read.
RemusDB, the best paper award winner, was an interesting talk that showed how VM-replication now performs well enough to be a way to provide High-Availability for any arbitrary database implementation. While this approach does make for a quick-and-dirty HA solution that deals with the primary failing, I'm not sure a VM level solution would work when the failed primary restarts and wants to rejoin the master-slave pair. Nevertheless, this will probably make a fun read for anyone interested in database systems.
HyPer -- a demo from some of the guys at TU-Munich , HYRISE -- from HPI and several others in academia have been playing with ideas for main-memory systems that can provide good OLTP performance while also supporting a reasonable OLAP workload. Their argument is that in most cases, you don't really need to have two separate systems -- one for OLTP and one for OLAP. I guess it is back to "one-size fits all" now eh?
There was also a cool paper on serializable snaphot isolation for replicated databases optimized for high update rates from folks at the University of Sydney and Seoul National University.
Industrial Talks
Google described Tenzing a SQL engine on MapReduce. The interesting part was that they worked with the MapReduce team quite a bit to make it possible to implement reasonably efficient join plans. The speaker flashed some slides that seemed to indicate that the per-node performance of Tenzing was "comparable" to a commercial database.
Ben Reed talked about "Inspector Gadget" -- a debugging tool for Pig that is currently in use at Yahoo! and has been open sourced as part of Pig 0.9.
Other Stuff
There were a bunch of interesting efforts around Hadoop and MapReduce that I'll write about in more detail later. There seemed to be some interest at the intersection of crowdsourcing and databases -- I'm still not sure I understand the opportunities there.
Tuesday, August 16, 2011
More on Disruptions
Another non-technical post. I was thinking through the amazing variety of industries in which web and related technologies have caused disruptive changes. There's a whole bunch of disruptions along the theme of monetizing the "long tail" --
And now the IT industry itself is possibly undergoing several disruptive changes:
Some of these disruptions are likely to have a small effect, and some of these are probably going to change the landscape of IT. It sure is an interesting time to be in technology!
| Long Tail Disruptions | ||
|---|---|---|
| Existing Industry | Disruptive Technology | Companies |
| Media Advertising | Online Ad networks, exchanges | AdSense |
| Retail | Online Retail/Auctions | Amazon, eBay |
| Banking | P2P Lending through web-based apps | Lending Club |
| Hotels, B&B | P2P Space Sharing through web-based apps | AirBnB |
| Content Publishing | Self Publishing with hosted blogging platforms | Blogger, WordPress, etc. |
| Discounted High-End Brand Retail | Web, Social Media +Daily Deal Email | Gilt.com, Fab.com, ... |
| Tax Accounting | Web-based Apps | TurboTax |
| Financial Advice | Web-based Apps | Mint.com |
| Broadcast Television | Streaming Video | Netflix, Hulu |
And now the IT industry itself is possibly undergoing several disruptive changes:
| IT Disruptions | ||
|---|---|---|
| Middleware (DBs, AppServers, etc.) | PaaS | Amazon Web Services, Google AppEngine, Force.com, Heroku, SpringSource, CloudFoundry, Rackspace Cloud |
| Data Warehousing | MapReduce, Hadoop | Yahoo, Hortonworks, Cloudera, IBM, ... |
| Short Request Processing | NoSQL stores | DataStax, Couchbase, Grid vendors |
Some of these disruptions are likely to have a small effect, and some of these are probably going to change the landscape of IT. It sure is an interesting time to be in technology!
Monday, August 8, 2011
HBase and Column Stores
I've been asked this a few times -- how would you compare the column store on Hadoop that we built (CIF) with HBase? HBase offers column families that are stored separately -- so, you should be able to store each column in a separate file if you put it in its own column family. This should work, and you should be able to get some amount of I/O elimination when scanning a small subset of columns from a much larger table, HBase introduces several inefficiencies in comparison to using the approach in our paper.
- Path length: Reading from HBase instead of directly reading a file (or a set of files) from HDFS means each byte now flows through more code. Data gets read off the disk by the DataNode process in HDFS, then it moves to the DFSClient in the HBase region server, and finally moves to the (key,value) pair returned by the InputFormat that reads using the HBase client object. These additional steps the data has to travel certainly adds overhead.
- Read logic: The read logic requires checking in at least two places before a row can be returned -- the SSTable on disk, and the state in memory in the Memtable (to use Bigtable terms). This is also additional overhead compared to simply reading the bytes off HDFS.
- Schema free: HBase wasn't designed to be used with fixed schemas for a table -- as a result, every row that is stored also stores the names of every column in that row. Knowing a schema allows CIF to store the metadata separately. While in HBase the repetition of the column names can be ameliorated by compressing away the SSTables, this still has a cost in terms of CPU cycles spent decompressing this data while reading. Again, more unnecessary overheads.
- Load speeds: If you aren't using a special bulk-load API and instead use the standard insert API to insert a new batch a single row-at-a-time, you'll send all the data twice over the network -- once to the logs, and a second time when the SSTables get replicated. If you're network bound during load -- and you should be if you are replicating, and you're not doing any crazy processing -- you'll be at half the load pace as you could get to with CIF.
- MapReduce Outputs: This one's a little tricky -- it is not clear how to make sure that an OutputFormat that takes the results of a MapReduce job and inserts it into HBase in a way that is compatible with MapReduce's fault-tolerance assumptions. If the OutputFormat inserts key-values directly into HBase, and then halfway through, the task fails -- there's no way to "roll-back" the stuff already inserted into HBase. The last I checked, you couldn't do an arbitrary insert sequence in an atomic way with HBase. There may be application specific ways out of this -- but with CIF, you simply end up writing a new set of files -- if the task fails, you delete them as part of the cleanup. Easy.
While HBase could be used as a columnar storage layer for scan-heavy applications, it would probably be a lot slower. However, if you need to support, point lookups, updates, and deletes -- this cost is justifiable. For applications that are append-only, and don't need to deal with point updates, CIF provides an alternative with a much higher performance.
An easy way to verify this would be to run a simple benchmark and measure the scan performance of CIF and HBase:-) I'll try and do that when I get a chance and post the results.
An easy way to verify this would be to run a simple benchmark and measure the scan performance of CIF and HBase:-) I'll try and do that when I get a chance and post the results.
Saturday, July 30, 2011
Hadoop: A Disruptive Technology?
This is going to be a rather non-technical post ... you have been warned :-)
Clayton Christensen's thesis (Innovator's Dilemma) more than a decade ago was that rational management practices of listening to your customers, and building and investing in what solves your customer's problems can lead you astray in the context of disruptive technologies. I've heard the phrase "Hadoop is a disruptive technology" in various contexts. I wondered ... does it really hold true according to Christensen's classic definition?
For a technology to be "disruptive", it should satisfy three requirements
Assuming that "big warehouse" vendors are the established leaders in the market, I'd guess that this is true. Big warehouses are messy and complicated to install, configure, tune, and get running. Hadoop is certainly simpler to install. Warehouses are usually deployed with non-commodity storage/networking. Hadoop runs on cheap commodity boxes. Is it simpler to use? That could go either way. If your problem fits in SQL, relational warehouses do an amazing job. Writing MapReduce programs is a good bit more work than writing a SQL query. Oh, and Hadoop is definitely cheaper :-) I'd give this a +0.75
Emerging Markets/ Value Networks
This is an easy +1. No one is clamoring to replace their big enterprise warehouse or even their big data marts with Hadoop. It is not clear how big the market is for Hadoop and related technologies. It isn't entirely clear what the market is. The early users have been big web companies that need to analyze web pages, search logs, and click logs. None of this data typically goes into a big relational warehouse. Monash has been arguing that the predominant driver for Hadoop has been the "big bit bucket" use case. Anant Jhingran alluded to many emerging use cases in enterprises -- most of these fall under the kinds of analytics that are/were not commonly done in traditional warehouses. The places where Hadoop is getting interest is not from the sort of enterprises/departments/groups who have typically bought warehouses to solve their data analysis needs.
Unattractive to Market Leaders and their Customers
Traditional enterprises don't and can't use Hadoop as their central data warehouse. Not today, and perhaps not in the near term either. The big central EDW is typically way more complicated than a typical Hadoop cluster - there is a complex ETL system feeding the beast, there are a bunch of tools producing and sending out reports, and there may be other ETL-off ramps feeding smaller data marts. Big EDW customers use complex SQL, many reporting tools that work with the warehouse, advanced features like views, triggers, and often even transactional updates. Big enterprises looking for an EDW solution simply cannot use Hadoop today. As a result, this is not the most attractive technology for big warehouse customers. Again, a +1.
That's 2.75/3. Neat. All this talk of Hadoop being a "disruptive technology" is not hot air after all. It does fit Christensen's definition rather well!
Clayton Christensen's thesis (Innovator's Dilemma) more than a decade ago was that rational management practices of listening to your customers, and building and investing in what solves your customer's problems can lead you astray in the context of disruptive technologies. I've heard the phrase "Hadoop is a disruptive technology" in various contexts. I wondered ... does it really hold true according to Christensen's classic definition?
For a technology to be "disruptive", it should satisfy three requirements
- It is a simplifying technology -- cheaper/easier than established technologies
- Commercialized first in emerging or insignificant markets
- The market leader's biggest customers generally don't want to and initially can't use it
Assuming that "big warehouse" vendors are the established leaders in the market, I'd guess that this is true. Big warehouses are messy and complicated to install, configure, tune, and get running. Hadoop is certainly simpler to install. Warehouses are usually deployed with non-commodity storage/networking. Hadoop runs on cheap commodity boxes. Is it simpler to use? That could go either way. If your problem fits in SQL, relational warehouses do an amazing job. Writing MapReduce programs is a good bit more work than writing a SQL query. Oh, and Hadoop is definitely cheaper :-) I'd give this a +0.75
Emerging Markets/ Value Networks
This is an easy +1. No one is clamoring to replace their big enterprise warehouse or even their big data marts with Hadoop. It is not clear how big the market is for Hadoop and related technologies. It isn't entirely clear what the market is. The early users have been big web companies that need to analyze web pages, search logs, and click logs. None of this data typically goes into a big relational warehouse. Monash has been arguing that the predominant driver for Hadoop has been the "big bit bucket" use case. Anant Jhingran alluded to many emerging use cases in enterprises -- most of these fall under the kinds of analytics that are/were not commonly done in traditional warehouses. The places where Hadoop is getting interest is not from the sort of enterprises/departments/groups who have typically bought warehouses to solve their data analysis needs.
Unattractive to Market Leaders and their Customers
Traditional enterprises don't and can't use Hadoop as their central data warehouse. Not today, and perhaps not in the near term either. The big central EDW is typically way more complicated than a typical Hadoop cluster - there is a complex ETL system feeding the beast, there are a bunch of tools producing and sending out reports, and there may be other ETL-off ramps feeding smaller data marts. Big EDW customers use complex SQL, many reporting tools that work with the warehouse, advanced features like views, triggers, and often even transactional updates. Big enterprises looking for an EDW solution simply cannot use Hadoop today. As a result, this is not the most attractive technology for big warehouse customers. Again, a +1.
That's 2.75/3. Neat. All this talk of Hadoop being a "disruptive technology" is not hot air after all. It does fit Christensen's definition rather well!
Sunday, July 24, 2011
RCFile and CIF
The benefits of using columnar storage for relational data is well known. The "Column-store for Hadoop" paper I recently blogged about focuses on the advantages of using CIF for complex variable-length data types like maps, arrays, nested records etc. Not surprisingly, it turns out that even if the data is flat and well-structured, CIF has two advantages over RCFile:
Suppose that you were only reading X, ideally, you'd want to read 4 * 100M ~ 400MB of data. With RCFile, you'd open each of the 175 blocks, read a small portion of the data there (~2.28MB) for X, then move on to the next block. With the CIF layout where you put each column in a separate file, you'd only read
~7 HDFS blocks to read all the X values. If you were only scanning Y, this would be 157 blocks, and for Z, 13 blocks. If the actual processing you were doing on the data were simple, such as just adding up the numbers -- which is typically the case for relational workloads, the per-block overheads (opening the block, interpreting the RCFile headers, seeking to the right place, etc.) become very substantial very quickly. As a result, CIF starts to have a major advantage over RCFile for wide rows where only a small number of columns are being scanned.
The second advantage is easier to understand. Given that HDFS is an append-only file system, adding derived columns while guaranteeing locality for the three replicas is very difficult with RCFile. Consider that you wanted to add a new column T to the dataset above that was computed by analyzing the string Y. An example would be some kind of feature extractor applied on a URL field. Now, this field T needs to be stored on the same nodes that the (X,Y,Z) columns for the row are stored on. The only way to guarantee this with the current design of RCFile is to re-write the file with (X,Y,Z,T) so that all the columns are organized and laid out correctly in the same HDFS block.
With CIF, the above is easily accomplished by adding the T data in a separate file and placing it next to the X,Y,Z files in each of the split directories of the dataset (Section 4.2 in the paper explains split-directories.) The RCFile design will need to be changed significantly using the ideas in CIF to accommodate such a feature.
The other side: RCFile advantages
The biggest advantage of RCFile is its simplicity. It fits beautifully within HDFS's constraints. CIF requires changing the HDFS placement policy (possible Hadoop-0.21.0 onwards) and also requires tracking a bunch of additional metadata. It also ends up creating a larger number of files, which could cause additional pressure on the namenode. However, for many deployments this should not be a major issue. There's a detailed discussion of this in the paper.
- When you read a dataset laid out in CIF, you end up touching fewer HDFS blocks than you would with RCFile.
- It is possible to add derived columns in a way that they are co-located correctly with the existing data. With RCFile, as it stands, the only option is to re-load the entire dataset.
Let me explain the first point with some numbers. Assume you're reading a dataset with three columns: a 4-byte integer (X), a 100 byte string (Y), and an 8-byte float (Z). Further, assume that you have 100 million rows. That gives us 100M * (112) = 11200Mi bytes ~ 11.2 GB. Assuming 64MB blocks, the data will be laid out over ~175 blocks when using RCFile. I'm completely ignoring the metadata overheads.
Suppose that you were only reading X, ideally, you'd want to read 4 * 100M ~ 400MB of data. With RCFile, you'd open each of the 175 blocks, read a small portion of the data there (~2.28MB) for X, then move on to the next block. With the CIF layout where you put each column in a separate file, you'd only read
~7 HDFS blocks to read all the X values. If you were only scanning Y, this would be 157 blocks, and for Z, 13 blocks. If the actual processing you were doing on the data were simple, such as just adding up the numbers -- which is typically the case for relational workloads, the per-block overheads (opening the block, interpreting the RCFile headers, seeking to the right place, etc.) become very substantial very quickly. As a result, CIF starts to have a major advantage over RCFile for wide rows where only a small number of columns are being scanned.
The second advantage is easier to understand. Given that HDFS is an append-only file system, adding derived columns while guaranteeing locality for the three replicas is very difficult with RCFile. Consider that you wanted to add a new column T to the dataset above that was computed by analyzing the string Y. An example would be some kind of feature extractor applied on a URL field. Now, this field T needs to be stored on the same nodes that the (X,Y,Z) columns for the row are stored on. The only way to guarantee this with the current design of RCFile is to re-write the file with (X,Y,Z,T) so that all the columns are organized and laid out correctly in the same HDFS block.
With CIF, the above is easily accomplished by adding the T data in a separate file and placing it next to the X,Y,Z files in each of the split directories of the dataset (Section 4.2 in the paper explains split-directories.) The RCFile design will need to be changed significantly using the ideas in CIF to accommodate such a feature.
The other side: RCFile advantages
The biggest advantage of RCFile is its simplicity. It fits beautifully within HDFS's constraints. CIF requires changing the HDFS placement policy (possible Hadoop-0.21.0 onwards) and also requires tracking a bunch of additional metadata. It also ends up creating a larger number of files, which could cause additional pressure on the namenode. However, for many deployments this should not be a major issue. There's a detailed discussion of this in the paper.
Friday, July 15, 2011
Spinnaker, Paxos, and Gaios
Here's a great paper from Bolosky and others at Microsoft that demonstrates that Paxos can indeed be used as a high-volume replication protocol. They argue that a Paxos-based storage service can provide performance close to what the underlying hardware can support. You don't have to resort to simple primary-backup schemes which make it difficult to deal with arbitrary machine restarts. Also, you don't have to give up sequential consistency for performance and deal with the complications of eventual consistency. The crux of their argument is: for a system that is in a single datacenter, and needs to use commodity networking and disks, the Paxos implementation will certainly not be the bottleneck.
They implemented this in the context of a storage system called Gaios. The paper has plenty of implementation details and performance results. They even ran an OLTP benchmark on SQL Server configured to use Gaios storage. Neat stuff!
Spinnaker exploits the same ideas as Gaios, but the exposes a user-programmable key-value store API instead of building scale-out storage. The results from Gaios independently verify the arguments we tried to make in the Spinnaker paper -- you can use a consensus algorithm for data replication in a scale-out system without sacrificing performance.
They implemented this in the context of a storage system called Gaios. The paper has plenty of implementation details and performance results. They even ran an OLTP benchmark on SQL Server configured to use Gaios storage. Neat stuff!
Spinnaker exploits the same ideas as Gaios, but the exposes a user-programmable key-value store API instead of building scale-out storage. The results from Gaios independently verify the arguments we tried to make in the Spinnaker paper -- you can use a consensus algorithm for data replication in a scale-out system without sacrificing performance.
Thursday, July 14, 2011
Column Stores and Hadoop
Switching gears a bit from the NoSQL to the Hadoop world ... here's a quick preview of some work we did on storage organization on Hadoop. We started this work to investigate how a columnar storage layer could be implemented for Hadoop and if it would lead to any insights that weren't already known in the context of parallel DBMSs. It turned up some pretty interesting results.
First, we built an InputFormat/OutputFormat pair on Hadoop v-0.21 that uses some of the new APIs for a pluggable BlockPlacementPolicy. We gave it a rather inventive name -- CIF and COF-- for ColumnInputFormat and ColumnOutputFormat :-) Instead of using a PAX-like layout with RCFile, CIF lets you you true columnar storage where each column is stored in a separate file. As one would expect, when you scan only a small number of columns from a much wider dataset, CIF eliminates the I/O for the unnecessary columns and improves your map-phase performance compared to SequenceFiles and RCFile.
Second, most of the literature on columnar processing in DBMSs usually deals with atomic types -- we looked at more complex types that are typically used in the Hadoop environment -- lists, maps, and nested records. These are all typically variable length columns. Being able to automatically avoid deserialization for these complex types when they're not accessed during the MapReduce job turns out to be a nice performance boost.
We combined the two ideas above to build a novel skip-list based Input/OutputFormat called CIF-SL. It lets you eliminate I/O for columns that you don't need in a job. Also, it lets you use lazily decompress and deserialize columns that are only accessed for some of the records during a MapReduce job. This can lead to substantial CPU savings. If it turns out that if you access a particular column for only a small fraction of the records you scan,CIF-SF can provide a pretty substantial advantage over plain CIF.
We wrote up these findings in a paper for PVLDB with details of the APIs, examples, an implementation sketch, and a performance evaluation. This paper is much simpler than Spinnaker paper, and a much more fun read :) Avrilia Floratou, who did most of the engineering for this project during her internship at Almaden, will present this at VLDB this fall.
First, we built an InputFormat/OutputFormat pair on Hadoop v-0.21 that uses some of the new APIs for a pluggable BlockPlacementPolicy. We gave it a rather inventive name -- CIF and COF-- for ColumnInputFormat and ColumnOutputFormat :-) Instead of using a PAX-like layout with RCFile, CIF lets you you true columnar storage where each column is stored in a separate file. As one would expect, when you scan only a small number of columns from a much wider dataset, CIF eliminates the I/O for the unnecessary columns and improves your map-phase performance compared to SequenceFiles and RCFile.
Second, most of the literature on columnar processing in DBMSs usually deals with atomic types -- we looked at more complex types that are typically used in the Hadoop environment -- lists, maps, and nested records. These are all typically variable length columns. Being able to automatically avoid deserialization for these complex types when they're not accessed during the MapReduce job turns out to be a nice performance boost.
We combined the two ideas above to build a novel skip-list based Input/OutputFormat called CIF-SL. It lets you eliminate I/O for columns that you don't need in a job. Also, it lets you use lazily decompress and deserialize columns that are only accessed for some of the records during a MapReduce job. This can lead to substantial CPU savings. If it turns out that if you access a particular column for only a small fraction of the records you scan,CIF-SF can provide a pretty substantial advantage over plain CIF.
We wrote up these findings in a paper for PVLDB with details of the APIs, examples, an implementation sketch, and a performance evaluation. This paper is much simpler than Spinnaker paper, and a much more fun read :) Avrilia Floratou, who did most of the engineering for this project during her internship at Almaden, will present this at VLDB this fall.
Saturday, July 9, 2011
HBase, Hadoop, and Facebook Messages
If you were at the Hadoop summit and watched Karthik Ranganathan’s talk, you know how Facebook now uses HBase to store all the inbox messages. It was a fun talk and Karthik shared many of the hard-won lessons from deploying and maintaining a large application on HBase and Hadoop/MapReduce. Here are a few observations:
Karthik and the rest of his team at Facebook didn’t choose Cassandra even though they have the necessary skills and expertise at Facebook to do this. In fact, Cassandra was originally built by Facebook engineers to store and index their inbox messages. Why? In fact, one of the audience members also asked this question. As we argued in the Spinnaker paper, you don’t want to force your application developer to deal with eventual consistency unless your availability needs cannot be met any other way. Writing automatic conflict resolution handlers is messy work, and as your application gets more complicated than a shopping cart, it is increasingly more difficult to reason about it. HBase with its easier consistency model likely made life much easier for the team building the messages service. Karthik's response was essentially the same.The availability guarantees provided by HBase are probably sufficient for the Facebook messages app. Let's do some quick calculations: on a cluster with about 100 nodes, if you expect that a regionserver crash occurs every 30 days, and conservatively, it takes about 10 minutes to recover, the availability of a row in HBase is approximately: 0.999768. (I'm just using 1 - MTTR/MTTF and making a whole bunch of simplifying assumptions.) If all the data for a user is stuffed into a single row, which seemed to be the case in FB’s design, this is perfectly acceptable availability: for a user that visited his message box twice every day, this would mean 0.169 "Not Available" errors a year. Pretty reasonable.
On the other hand, ff you have a more complex application, and you needed access to *all the rows* to support your application, the availability of your application would be 0. 999768 ^ 100 = 0.977115. Although this looks close enough to the previous number, this is really bad. The same user that visited his inbox twice a day would see about 16 "Not Available" errors a year. That's more than an error every month. That could make for unhappy users. By designing the application appropriately, the Facebook guys were able to fit well within the availability guarantees that HBase can provide. Nice job!
Spinnaker still has other performance advantages ... but that's for another blog post :-)
Thursday, June 30, 2011
2011 Hadoop Summit
I was at the Hadoop Summit in Santa Clara today. It was fun. The long rumored Hadoop spin-off was confirmed yesterday -- a bunch of the core infrastructure team under Eric14 is now a separate company called HortonWorks. Their current business plan is to sell training, consulting, and services around Apache Hadoop.
The post surprising part of the summit was the sheer number of new VC funded startups that were there. Last year, the major ones were Cloudera, Datameer, and Pentaho. This year a host of new companies appeared: MapR, Zettaset, Arista, PervasiveDataRush, SyncSort, and DataStax (previously Riptano).
One observation I had was that there seems to be a flurry of activity in the scalable PubSub system space. At least five systems were discussed/mentioned:
Of these I have a basic understanding of Kafka and Hedwig, but I haven't used either.They seem to have made different design choices. Kafka is aimed squarely at log collection ... they argue that some of their API choices were better than the ones offered by Scribe. Hedwig seems closer to a true scale-out queuing system with guaranteed in-order at-least-once delivery. It'll be fun to do an in-depth comparison at some point.
The post surprising part of the summit was the sheer number of new VC funded startups that were there. Last year, the major ones were Cloudera, Datameer, and Pentaho. This year a host of new companies appeared: MapR, Zettaset, Arista, PervasiveDataRush, SyncSort, and DataStax (previously Riptano).
One observation I had was that there seems to be a flurry of activity in the scalable PubSub system space. At least five systems were discussed/mentioned:
- Kafka from LinkedIn
- Scribe from Facebook
- Flume from Cloudera
- Hedwig from Yahoo
- Data Highway (Yahoo)
Of these I have a basic understanding of Kafka and Hedwig, but I haven't used either.They seem to have made different design choices. Kafka is aimed squarely at log collection ... they argue that some of their API choices were better than the ones offered by Scribe. Hedwig seems closer to a true scale-out queuing system with guaranteed in-order at-least-once delivery. It'll be fun to do an in-depth comparison at some point.
Friday, June 24, 2011
An Informal Availability Comparison Between Hbase and Spinnaker
An important design goal in scale-out structured storage systems (“NoSQL” systems) is availability. Availability is usually defined as 1 – (MTTR/(MTTF + MTTR)). MTTR, the Mean-Time-To-Repair, is the duration for which a data item is not available for reads or writes when a node fails. MTTF is the Mean-Time-To-Failure.
We did a simple experiment measuring MTTR for both Spinnaker and HBase and learned some interesting stuff, but we didn’t have room for it in the paper.
To compare HBase and Spinnaker, we used the following setup: a single client picks a random node in the cluster and starts writing data. Consecutive keys are used and a single random value of 1KB is written. After a predetermined amount of data is written, we trigger a failure of the node that was processing the writes for this key-range. We do this by killing the leader of the cohort in Spinnaker. For HBase, we killed the regionserver process for the key-range.
We measured the time taken between the first failed write and the first successful write after that as the unavailability window experienced by the client. In both cases, we split this unavailability window into two parts: the time taken to detect a failure and the time taken to actually recover. Both systems exploit Zookeeper for failure detection. The average time to detect a failure can be configured by adjusting the Zookeeper session timeouts and is set to 2 seconds. In the experiment below, we subtract the failure detection times and only report the actual recovery times.

The picture above shows that for HBase, the recovery time grows linearly with the amount of data that was written to the system before a failure occurred. For Spinnaker, the recovery time remains constant. Neat! This is not unexpected: when a node fails, the regions served by the failed regionserver become unavailable for both reads and writes. HBase needs to carry out multiple steps: First, the master node reads the log file (available in HDFS) of the failed regionserver and splits it into separate files for each region. Each of these regions is assigned to a healthy regionserver. These regionservers now replay the log file, construct the appropriate memtable, and make that region available for reads and writes. The total recovery time includes the time taken to first split the log, and then replay it before opening up for updates. This is clearly proportional to the size of the log. This number can be decreased by aggressively flushing the in-memory data structures to on-disk SSTables more frequently (decreasing the memtable flush limit) and checkpointing. While this will reduce the unavailability window, it severely affects write performance. Typical configurations suggest using around half the available memory for the memtables. With 16 gigabytes of memory on each server, the unavailability window on failure is over 13 minutes. As the available memory on a server increases, this window gets longer.
In the case of Spinnaker, the ranges on a failed master become
unavailable for writes until a new master is elected. The replication protocol in Spinnaker ensures that the new master only needs to re-propose the values since the last-known committed value. This is often less than 1 second’s worth of data, and is independent of the size of the log. As the picture shows, the unavailability window of Spinnaker is relatively constant irrespective of the amount of data written.
Spinnaker continues to be available to service weak reads from the other members in the cohort. Strongly consistent reads are serviced by the master, and therefore are unavailable until a new master is elected, just like in the case of writes. In contrast, HBase is unavailable for both reads and writes. Although, I suspect it wouldn’t be too difficult to modify HBase to return a stale read while the recovery is running.
This interesting property is a consequence of the fact that the HBase design does not provide for a “warm standby” and delegates replication and consistency entirely to the filesystem (HDFS). While I’m not aware of any published work, I suspect there are interesting ways in which HDFS and the HBase design can be modified reduce the unavailability window when a node fails.
Eventually consistent systems like Cassandra continue to be available for both reads and writes after failures by sacrificing consistency. By definition, their MTTR is 0 as long as any node in the system is alive, and therefore the availability is 100%. We did not include Cassandra in this experiment.
Wednesday, June 15, 2011
Synergy Shout-Out
I just wanted to give a quick shout-out to the makers of Synergy (http://synergy-foss.org/). This is a nifty little tool that lets me share a single keyboard and mouse across my Windows machine and my Ubuntu laptop without any hardware. It simply uses a TCP /IP connection between the machines to accomplish this.
I’m stuck using a windows machine at work for various reasons. The reasons have been steadily dwindling over the months, but I still need PowerPoint every once in a while. Most of my development is on the Ubuntu laptop. Synergy lets me use three screens connected to my two machines seamlessly. My Ubuntu machine powers two displays and the windows machine powers one display: I can slide my mouse across all three displays. What’s better – I can even copy-paste across the two machines. Neat stuff!
Thursday, June 9, 2011
Spinnaker and "NoSQL"
Spinnaker and “NoSQL"
Spinnaker is an interesting research project I worked on in the “NoSQL” space. We have a paper describing the system in PVLDB. Since VLDB is still a few months away, I figured I’d write up a quick-and-easy summary, and some interesting perspective that we didn’t have room for in the paper.
Spinnaker is an experimental datastore that is designed to run on a large cluster of commodity servers in a single datacenter. It features key-based range partitioning, 3-way replication, and a transactional get-put API with the option to choose either strong or timeline consistency on reads.
There are three big architectures in the scale-out NoSQL space: Bigtable, Dynamo, and PNUTS. In Spinnaker, we tried to tackle the question of how one would design a key-value store if we weren’t constrained by any existing systems. The goal was to build a scalable key-value store with a reasonable consistency model, high availability, and good performance.
The Bigtable design, of course, leverages GFS. This made the design for Bigtable simple and elegant. It didn’t have to deal with replication and consistency – the filesystem took care of that. But there is a performance and availability cost associated with letting the filesystem take care of that.
Dynamo was great except for one big problem: eventual consistency. While this is a reasonable choice for super-duper-amazing-high availability, perhaps most applications would rather deal with an easier consistency model rather than eventual consistency? As the application gets more complicated than a shopping cart, programming against eventual consistency gets extremely confusing and tricky. This is a burden we don’t want to place on the application developer unless it is unavoidable.
PNUTS leverages a fault-tolerance pub-sub system that Yahoo had already built. This too probably has an associated scalability and availability cost. The pub-sub system is a central point of communication for all the write traffic and the whole system can only scale as far as this pub-sub system could scale. I’m guessing that PNUTS used a single server, hardened-with-hardware approach to making that pub-sub system work, which could be a scalability bottleneck. There have been a few scalable pub-sub system efforts since then -- Hedwig, Kafka, etc … Then again, we didn’t have one of these lying around, so we asked the question, what’s the ideal design if you were to build one of these key-value stores from scratch?
Spinnaker tries to bring the best of Bigtable, Dynamo, and PNUTS designs together.
Spinnaker doesn’t use a DFS or a central fault-tolerant pub-sub system. Instead, Spinnaker uses a consensus-based replication algorithm and leverages Zookeeper for coordination. We used the Cassandra codebase as the starting point for the Spinnaker design. The node architecture looks very much like Bigtable (with log structured maintenance of on-disk data using SSTables). I won’t go into the details of the architecture here; you can read the paper for that….the interesting finding was that the Spinnaker design can be competitive with an alternative like Cassandra that provides weaker consistency guarantees. Compared to Cassandra, we showed that Spinnaker can be as fast or even faster on reads and only 5% to 10% slower on writes. On node failure, if the node happened to be a ``leader’’ of a replication cohort, Spinnaker suffers short unavailability windows of under 2 seconds for writes to that key-range. Reads continue to be available. In comparison, HBase suffers from substantially longer unavailability windows when a node fails – for both reads and writes. Cassandra is eventually consistent, and therefore always available despite failures.
It was really interesting to see that a consensus based replication algorithm can provide pretty good performance. I do feel that more and more apps that really need to use a large scale-out key-value store probably don’t need the kind of durability guarantees that Spinnaker can provide. Spinnaker can be configured to provide durability of “2 out of 3 memories”. This improves a big boost to latency and throughput … but if that’s really the target, I’d look very carefully at a different system…. look for the next post J
Friday, June 3, 2011
AMP Lab
I was recently at the AMP Lab retreat. There’s a lot of interesting work going on at Berkely. Here are a few things that caught my attention:
- Datacenter OS
Lots of solid systems work under the general umbrella of figuring out how to do better resource management by looking at workload traces and driving improvements to scheduling, caching, some of my favorites were:
· DRF (Dynamic Resource Fairness) A scheduling algorithm that guarantees fair allocation and is strategy proof – an interesting and perhaps useful alternative when optimizing utilization is not always the right thing to do. There was a nice presentation from Ali Ghodsi that described why this was interesting and the value proposition of DRF when compared to a market-based allocation technique.
· Orchestra and Memento: Orchestra is a bunch of techniques for scheduling large data transfers like broadcasts and shuffles to minimize job completion times. Memento is a globally coordinated caching strategy for Hadoop-like deployments to help speed up completion times for small jobs.
· Performance Isolation: Doing good performance isolation beyond “number of cores” and amount of memory without substantial overhead has been tricky. There are a bunch of projects under this umbrella looking at better ways to do this for other resources such as disk I/O, power, and even memory bandwidth! (A project called RAMP ?). Performance isolation at the level of memory bandwidth is probably going to open up a whole new set of application frameworks that can be supported at the datacenter level.
- Spark
Spark is a deceptively simple project, and perhaps one of my favorites, that I think has just scratched the surface of what’s possible. Scala provides an interesting playground that could help bridge the gap between programming languages and query languages. Spark touches on some simple techniques that can be used in this space and provides a runtime that can use these techniques while also giving you a runtime that is Java-friendly (store de-serialized data , in-memory). Bagel is a neat implementation of BSP/Pregel APIs using the pieces in Spark. There’s some work on running SQL on RDDs for interactive queries: a quick-and-dirty way to get a toy version of Google’s Dremel. I think there are many interesting things to come in this space.
- New Application: Cancer Genomics
There were two very exciting presentations on the possibility of “big data” infrastructure helping find a cure for cancer! The first one was from David Haussler of UC Santa Cruz who talked about the data challenges in understanding cancer genomics. The second was from Taylor Sittler from UCSF. The interesting take-aways were that sequencing and SNP calling are not completely solved “easy” problems – there are interesting genetic variations, such as insertions, deletions, repeats that are still computationally expensive to discover from short-read sequencers. There’s plenty of computational work to do in understanding what changes are significant and why. The second talk from Sittler was also really fascinating – he identified two interesting applications:
· Automatically recommending a drug cocktail based on sequence information gathered from tumor and normal tissue. The analytics flow is assumed to have access to a drug target database which has information on what drugs affect what targets/pathways. A medical expert can use this list as a starting point for designing the treatment.
· Determining novel viruses: Looking at sequence data from sick individuals and classifying the reads into “human”, “known bacteria/viruses”, and “novel viruses”. This seemed somewhat easier than the previous problem, but perhaps I was missing something.
Subscribe to:
Posts (Atom)